
美国南加大学者在研究DeepSeek 24小时后,搞懂了模型降本的秘密
2025年蛇年春节前夕,DeepSeek彻底出圈了。
1月27日,DeepSeek应用登顶苹果美国地区应用商店免费App下载排行榜,在美区下载榜上超越了ChatGPT。同日,苹果中国区应用商店免费榜显示,DeepSeek成为中国区第一。
DeepSeek究竟厉害在哪里?近日,浙江大学计算机博士、美国南加州大学访问学者、《业务驱动的推荐系统:方法与实践》作者傅聪在与新浪科技沟通中,解析了DeepSeek成功出圈背后的技术原理。
目前,业界对于DeepSeek的喜爱主要集中在三个方面。第一,在技术层面,DeepSeek背后的DeepSeek-V3及公司新近推出的DeepSeek-R1两款模型,分别实现了比肩OpenAI 4o和o1模型的能力。第二,DeepSeek研发的这两款模型成本更低——仅为OpenAI 4o和o1模型的十分之一左右。第三,DeepSeek把这一两大模型的技术都开源了,这让更多的AI团队,能够基于最先进同时成本最低的模型,开发更多的AI原生应用。
那么,DeepSeek是如何实现模型成本的降低?同时还保证模型效果比肩OpenAI 4o和o1模型的呢?
在与新浪科技沟通中,傅聪在深入研究Deepseek开源论文24小时后表示:“Deepseek确实有两把刷子,他们通过Multi-Head latent Attention(MLA)和DeepSeek MOE架构,节省了大量的显存,进而实现底层算力的高效利用,以更低的成本,训练出更加出色的模型效果,这种技术思路,是在DeepSeek V2版本发布时就已经得到验证。”
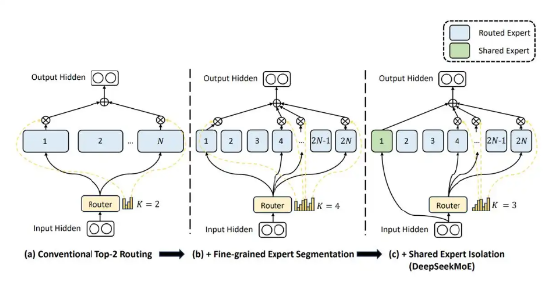
据傅聪介绍,目前,DeepSeek用于降低模型训练成本的技术,至少包括以下四类:
第一,DeepSeek使用了一种先进的、不需要辅助损失函数的专家加载均衡技术,该技术能保证每个token下,少量专家网络参数被真正激活的情况下,不同的专家网络能够以更均衡的频率被激活,防止专家网络激活扎堆。
“在DeepSeek V2时,他们在2360亿参数规模的模型上已验证了这一策略的有效性,这次DeepSeekV3他们在6710亿参数规模的模型上进一步验证了这一策略,这个规模基本接近头部玩家目前最好的商用模型参数规模,我们也看到deepseekV3所展示出的能力,在benchmark效果上与GPT4o和Claude-3.5能打个有来有回。”傅聪表示。
第二,DeepSeek还设计了一种“对偶流水线(Dual Pipeline)机制”,可以通过极致的流水线调度,把GPU中用于模型训练中数学运算的算力,和通信相关的算力在流水线执行过程中进行“并行隐藏”,实现了在训练过程所有的时间中GPU几乎不间断地进行运算。理论上,这个流水线机制,可以让GPU的指令执行流水线中的“气泡”,比目前最好的技术设计降低接近一半,同时只略微增加显存的消耗。
第三,DeepSeek技术团队还充分利用专家网络被稀疏激活的设计,限制了每个token被发送往GPU集群节点(node)的数量,这使得GPU之间通信开销稳定在较低的水位。
第四,DeepSeek还实现并应用了FP8混合精度训练的架构,在架构中的不同计算环节,灵活地、交替地使用FP8、BF16、FP32不同精度的“数字表示”,并在参数通信的部分过程也应用了FP8传输。在大大加快计算速度的同时,也降低了通信开销。
模型成本优化外,对于如何提升模型效果?傅聪指出,除了沿用MLA架构外,DeepSeek还应用了多token预测技术(multi token prediction),使得模型训练的时候,会同时预测序列后面更远的、不同位置的token。这可能使得模型有了对“更远未来”的感知能力,以此增强模型的效果。
在傅聪看来,DeepSeek V3是一个基础模型,事实上距离OpenAI的o1还有较大距离。真正帮助DeepSeek追赶o1的是最新模型DeepSeek-R1,该模型几乎单纯使用强化学习技术进行“后训练”,让模型的推理能力得到了极大的提升。简单来说,就是让R1模型在“后训练”过程中,通过学习CoT(思维链)的方式,一步一步推理得出结果,而不是直接预测答案。“这一方案,也是圈子内大家对OpenAI o1模型实现路径的猜测,而Deepseek用极快的速度,验证了这一路径的可行性!”傅聪表示。
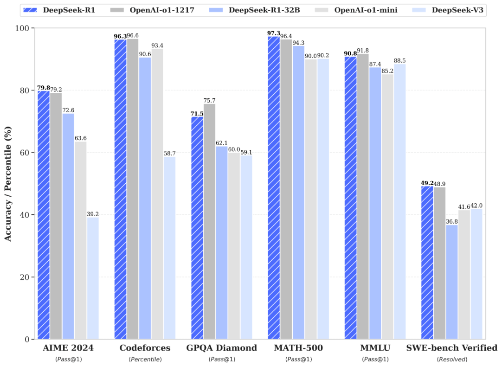
在傅聪看来,DeepSeek R1所带来的技术突破,不仅证明了强化学习(RL)以及 inference time scaling law这条路子的可行性。还证明了即便是小模型(7~13B),也可以通过CoT + RL实现思考和自我演化(self- evolution),大幅提升推理能力。之前小模型往往因为幻觉严重,备受诟病,现在看来很多小模型在充分优化后,也具备在应用场景落地的潜力。
此外,R1的出现也会让学界和产业界更加重视合成数据,“后训练”时代,对基于CoT思想的优质合成推理数据的需求,将会大大增加。

海量资讯、精准解读,尽在新浪财经APP